Helping you quickly find exactly what you are looking for is core to what Notejoy is all about. Search inside images & documents expands upon Notejoy's already robust search to help you query for text inside the images and documents you attach to notes.
When you upload an image to a note, we leverage machine learning and optical character recognition (OCR) technology to find all the text in the image, save it to our search index, and allow you to query for it when searching on Notejoy.
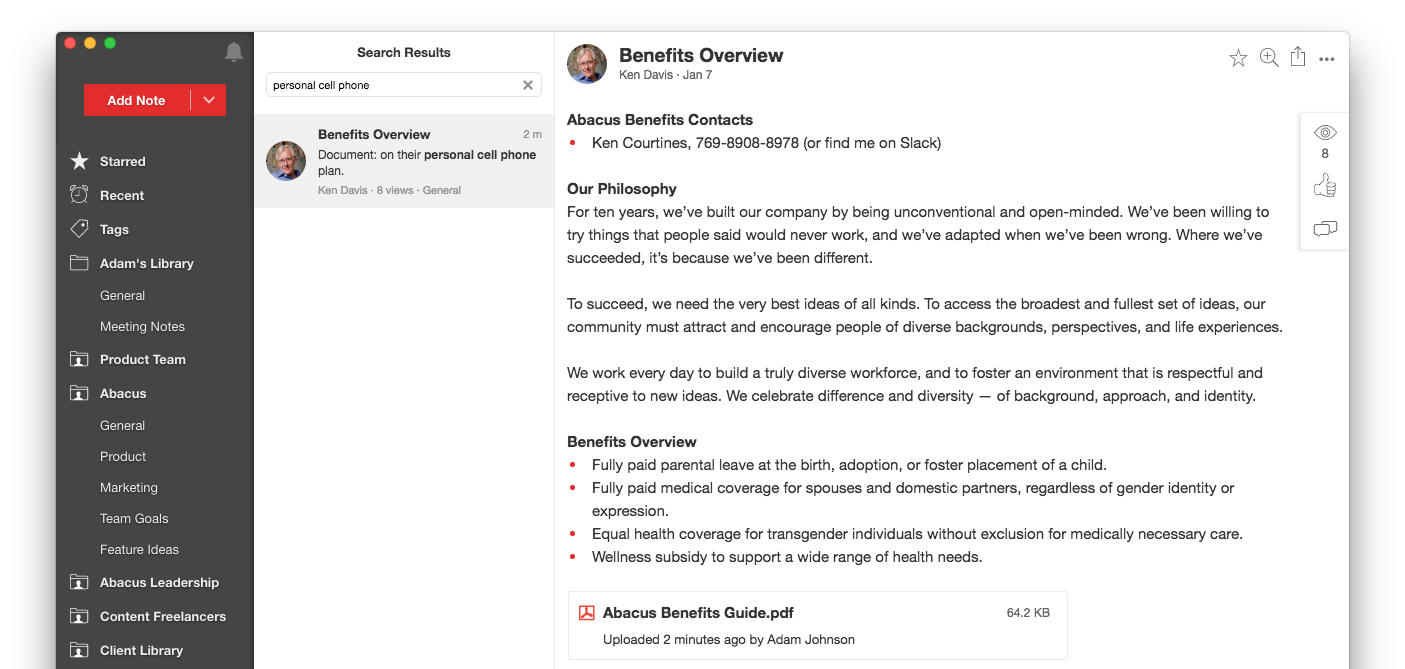
We do the same for documents that you upload or attach to notes: extract all the text from the document, add it to our search index, and make it queryable when you search. This even works great for scanned PDF documents, which we treat as images to extract all the text. We support searching inside PDF files, Microsoft Word files (including both .doc and .docx extensions) as well as Google Docs.
When you search, you'll now see search result snippets that start with Image or Document, indicating that your search term was found in the note's attached images or documents. You'll even see a snippet of your search text that was found in the image or document.
There are so many great ways to take advantage of this. Maybe you upload business card images you snap to Notejoy and now you can quickly search for a name to get back to the card.
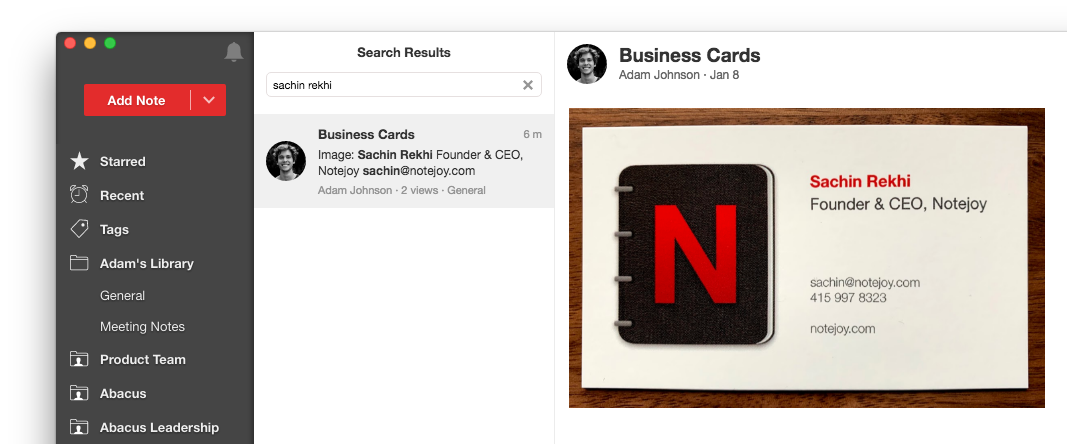
Or you can upload PDFs, Google Docs, and Microsoft Word files you've created and make them broadly searchable across the entire team.
Search inside images & documents is available to Notejoy Solo, Plus, or Premium subscribers. So if you haven't upgraded yet, learn more about our plans here.
More Details
- Notejoy indexes up to the first 5 images uploaded to a note as well as the first 5 documents uploaded to a note
- Notejoy indexes up to the first 20 pages of text within uploaded documents
- Notejoy cannot index text within password-protected PDF files
- Very large documents may not be indexed
- OCR technology is never perfect so you might find not all words present in an image are searchable
- Not all document's text can be extracted, depending on the way the document was originally generated